Chronique d’une typologie doublement guidée
-
Application sur la gen Z

Quels sont les éléments et objectifs de l’enquête ?
ADN a été missionné sur une étude pour le traitement de données et pour effectuer une typologie pour laquelle nous vous partageons ici le parcours méthodologique. Cette étude a été réalisé auprès de 806 individus âgés de 16 à 25 ans, l’objectif est de réaliser une typologie quantitative basée sur des variables comportementales de l’enquête permettant de confirmer les personae établis lors de la phase quali effectuée en amont. A ce stade 4 personae ont été mis en avant :nous vous en dévoilerons les noms ultérieurement, appelons les aujourd’hui « groupes » 1,2,3 et 4.
Comment aborder cette problématique de classification ?
Premiers essais : une approche classique via ACP et K-means… avec des résultats décevants !
Au vu du résultat de l’étude qualitative, nous savons que nous cherchons idéalement une solution en 4 classes. L’objectif étant si possible, de se rapprocher des types décrits dans cette analyse.
Nous avons réalisé une première ACP sur la base d’une sélection des items orientée sur la vision qualitative initiale. Les axes ainsi obtenus mélangent cependant des notions très différentes, raison pour laquelle nous ne donnons pas suite à cette piste. En effet, idéalement un axe est constitué de plusieurs items pour renforcer la thématique dont il traite. Or cette première analyse ne permettait pas de faire le lien entre les items constituant les axes.
De cet enseignement, nous remettons à plat les objectifs. La typologie que nous cherchons à effectuer traite de nombreuses informations : nous ne traitons pas un sujet ou un marché en particulier, mais plutôt l’ensemble des sujets de société pour la GEN Z.
Nous avons donc finalement décidé de sélectionner tous les items comportementaux possibles, en d’autres termes plutôt que de choisir les items a priori, nous préférons laisser sélectionner des items discriminants de la population a posteriori par les algorithmes.
Cette seconde ACP, calculée sur l’ensemble des items aboutie après diagnostic à retenir la solution en 18 axes : elle comporte le plus fort taux de variance expliquée, chaque axe étant constitué d’au moins 2 items fortement contributifs.
En appliquant l’algorithme K-means depuis ces 18 axes, nous obtenons un découpage dont le résultat est toutefois décevant : Un groupe avec 25% de l’échantillon est en sur-notation sur l’ensemble des items et c’est une configuration que nous voulons éviter. A noter que par ailleurs, les 3 autres types sont bien loin de la description qualitative.
Pour le 3ème essai, nous avons décidé de sélectionner parmi les 18 axes de l’ACP, seuls ceux qui portent sur les thématiques de l’analyse qualitative, en espérant retrouver un peu plus d’hétérogénéité entre les types. Nous en avons finalement sélectionné 11 sur les 18.
Nous obtenons une nouvelle solution qui comporte les mêmes problèmes que l’essai précédent : les types sont décrits par le fait de bien noter les batteries de questions. Ces types sont construits en s’appuyant principalement sur les corrélations « naturelles » qui existent entre les items d’une même question d’un questionnaire.
Conclusions sur ces premiers essais
Avec l’ACP seule, les moyens pour piloter les résultats sont limités : nous décidons alors d’appliquer notre méthode de typologie doublement guidée : comparée à l’association seule ACP / K-mean, celle-ci est plus efficace, avec de meilleurs résultats, et permet de disposer d’une souplesse de paramétrage beaucoup plus grande.
Qu’est-ce que la typologie doublement guidée ?
Il faut commencer par construire une segmentation de guidage : nous optons pour les questions les plus importantes à nos yeux pour expliquer les attentes des jeunes, à savoir la combinaison entre l’âge, la CSP et le revenu du foyer. L’idée étant que cette segmentation de guidage joue le rôle d’une « photographie » de notre échantillon. Ces caractéristiques socio-démographiques sont factuelles ; en particulier, elles ne sont pas soumises à interprétation. Nous obtenons à ce stade 16 segments de guidages.
Cette segmentation devient littéralement un guide pour la typologie, car les variables actives vont expliquer cette réalité, via une analyse discriminante : l’idée est de construire des axes qui expliquent la photographie proposée par la segmentation initiale. C’est ceci que nous appelons guidage de la typologie.
Si nous cherchions à construire notre résultat directement en 4 types via une K-means, en nous appuyant sur les axes discriminants, nous aurions appliqué ce que nous appelons une typologie simplement guidée. Cette méthode fonctionne globalement mieux que la méthode classique par ACP, car elle propose naturellement plus de variance entre les 4 types obtenus. Mais cette méthode nous permet en revanche difficilement de guider les résultats vers une vision déjà connue de notre marché, à savoir les 4 types de l’étude qualitative.
Pour réaliser un double guidage, nous appliquons une K-means initiée par la segmentation de guidage afin d’obtenir 16 types : cette solution n’est pas un résultat, mais bien une étape intermédiaire qui est soumise à l’institut. Il nous faut alors affecter ces 16 types ainsi obtenus aux 4 types qualitatifs, en s’appuyant sur la lecture des profils et le bon sens :
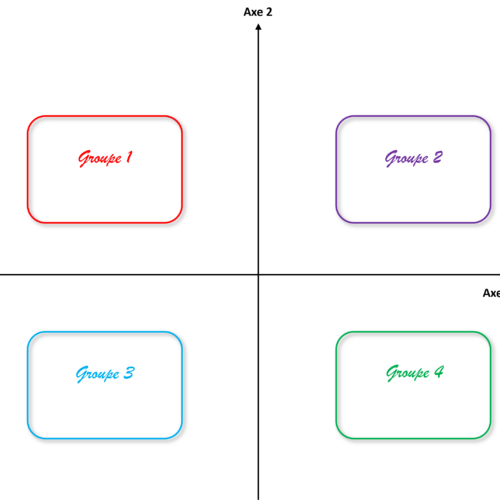
Il faut aussi limiter les déséquilibres de volumes des classes dans cette sélection. Ce regroupement est un nouveau guide, qui injecte la vision marché dans le résultat obtenu.
Une fois cette affectation validée, la segmentation de guidage est regroupée en 4 « méta-groupes », et c’est sur ceux-ci que nous appliquons l’algorithme K-Means. Cette fois-ci, le résultat est satisfaisant, voire au-delà de nos espérances : il questionne même les personae quali initiaux, en leur ajoutant des dimensions comportementales nouvelles par la lecture approfondie des profils. Ce seront finalement ces groupes qui seront retenus pour communiquer sur les résultats de l’enquête.
Qu’en conclure ?
- Effectuer une typologie à partir d’une ACP sur une sélection de variables actives consiste à partir pratiquement de zéro, c’est-à-dire agnostique de toute analyse préliminaire.
- Lorsque les personae ne sont pas prédéfinis, mais que nous souhaitons introduire une couche de flexibilité permettant d’affiner des paramètres à chaque étape, il est souhaitable de travailler avec une typologie simplement guidée.
- Lorsque de surcroît, les objectifs attendus sont clairs et que des personae sont pré-établis, il est plus efficace de passer par une typologie doublement guidée, qui permettra à l’expert du marché d’étudiée, d’influer sur les types obtenus.
Le guidage des analyses typologiques est recommandé par ADN, et a apporté satisfaction à chacune de ses applications. Si vous souhaitez en savoir plus sur la typologie guidée et nos méthodes d’analyses plus généralement, n’hésitez pas à prendre rendez-vous avec nos experts !
Vous aussi vous souhaitez tirer le meilleur parti de vos données ?
Nos équipes sont à votre disposition pour une démonstration personnalisée !